小程序升级:用DeepSeek解读MBTI人格测试结果
分享下用DeepSeek大模型为MBTI人格测试小程序添加AI解读功能。看起来简单,但实际上一点儿也不难😂,但也有不少坑。
项目背景
上次的预告:MBTI小程序升级记:从无法分享到联通的骚扰拦截! | AI之外
说干就干,我选择了DeepSeek作为AI服务提供商。我去年冲了10块,到现在都没用完😂。主要是现在免费的API一大堆,码代码也没必要直接用API,白嫖各大厂商抢占市场的福利就够了。CodeBuddy我都换了两三个帐号了,不过现在国际版的默认大模型也不知道是不是Claude4,也没关系,白嫖还挑啥😂。
AI解读系统流程图
整个AI解读系统的工作流程如下
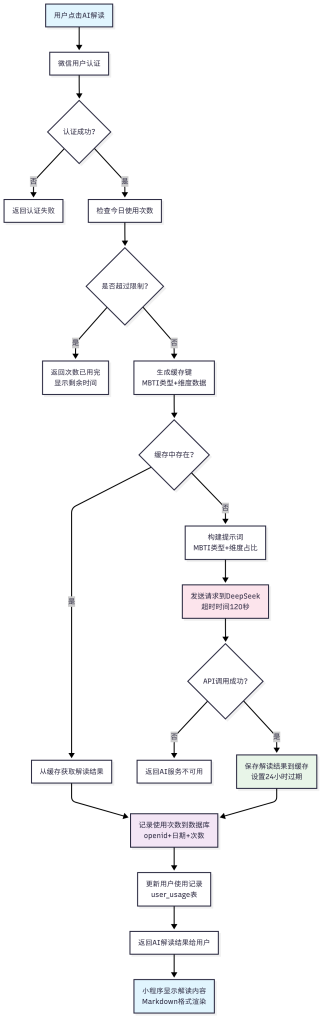
核心数据流转
- 用户认证层:验证微信用户身份,获取openid
- 使用限制层:检查每日使用次数(默认1次/天,不过一般情况下也没人有事没事就测试玩,当然我做这个小程序也就是纯粹为了水文章😂)
- 缓存查询层:根据MBTI类型和维度生成唯一缓存键
- AI调用层:构建提示词,调用DeepSeek API(120秒超时)
- 数据持久化层:缓存解读结果,记录使用统计
- 结果展示层:Markdown解析,富文本显示
数据库表结构
-- 用户使用记录表
user_usage (
openid VARCHAR(64), -- 微信用户ID
usage_date DATE, -- 使用日期
usage_count INT, -- 当日使用次数
created_at TIMESTAMP -- 创建时间
)
-- 解读缓存表
interpretation_cache (
cache_key VARCHAR(128), -- 缓存键(MBTI+维度哈希)
mbti_type VARCHAR(8), -- MBTI类型
dimensions JSON, -- 维度数据
interpretation TEXT, -- 解读内容
ai_provider VARCHAR(32),-- AI提供商
expires_at TIMESTAMP -- 过期时间
)
技术架构设计
后端技术栈
我让AI帮我设计了后端,主要考虑我服务器资源有限,所以选择了轻量级的技术栈(实际上目前没实现完):
- Node.js + Express.js:轻量级后端框架,适合快速开发
- MySQL + 连接池:数据持久化,使用连接池提高并发性能。毕竟之前的网站就用的mysql,没必要再安装其他数据库了。
- 文件缓存系统:避免重复调用AI接口,节省成本。
- AES-256加密:保护用户数据传输安全,目前这一步没实现。
- HMAC-SHA256签名:防止API被恶意调用。没实现,现在白嫖的API这么多,应该不会有人搞事情😅。
核心功能模块
backend/
├── routes/
│ ├── auth.js # 微信用户认证
│ ├── usage.js # 使用次数限制
│ └── interpretation.js # AI解读生成
├── services/
│ ├── ai-service.js # DeepSeek API调用
│ ├── cache-manager.js # 缓存管理
│ └── prompt-manager.js # 提示词管理
├── prompts/
│ └── mbti-interpretation.md # 人格测试结果解读提示词
└── config/
└── database.js # 数据库连接池
第一个坑:目录结构引起的API路由问题
问题背景
我有一个已经备案的网站,想把这个MBTI后端服务部署到现有网站下,而不是单独开一个域名。所以我设计了这样的目录结构:
/www/wwwroot/actorus/
├── index.html # 原网站首页
├── api/
│ └── mbti_ai/ # MBTI后端服务
│ ├── app.js
│ ├── routes/
│ └── ...
└── other_projects/ # 其他项目
以后如果有其他API项目,可以直接在api目录下新建目录,方便分类管理。
遇到的问题
小程序请求 https://www.actorus.top/api/mbti_ai/health 时,总是返回404 "API endpoint not found"。
Nginx配置解决
问题出在Nginx配置上。我需要将 /api/mbti_ai/ 路径的请求转发到Node.js服务:
server {
listen 443 ssl;
server_name www.actorus.top;
# 重要:这个location要放在 location / 之前
location /api/mbti_ai/ {
# 将 /api/mbit_ai/xxx 重写为 /api/xxx 再转发
rewrite ^/api/mbit_ai/(.*)$ /api/$1 break;
proxy_pass http://127.0.0.1:3000/;
# 其余配置
}
# 其余配置
}
关键点是location块的顺序:反向代理配置必须放在 location / 之前,否则所有请求都会被静态文件处理拦截。
第二个大坑:DeepSeek响应超时问题
问题现象
我将后端部署到服务器后,用手机测试发现点击"DeepSeek解读"后页面一直转圈,最后显示"网络连接失败"。我查看Nginx日志,发现大量504超时错误:
upstream timed out while reading response header from upstream
奇怪的是,我在本地测试时一切正常,30秒内就能收到DeepSeek的响应。
排查过程
- 网络连通性测试:在服务器上直接curl DeepSeek API,返回401(说明网络通)
- 简单脚本测试:在服务器上写了个最简单的Node.js脚本调用DeepSeek,成功返回。
- 日志分析:我查看DeepSeek后台,发现确实在扣费,说明请求发出去了。
这就很诡异了:明明扣费了,为啥我的服务收不到响应?
解决方案
经过反复测试,我发现问题出在两个地方:
- DeepSeek在高峰期响应很慢:线上环境下,生成一次完整的MBTI解读需要50-60秒,远超我设置的30秒超时,DeepSeek该升级升级服务器了!
- keep-alive连接复用问题:在低配服务器上,复用的TLS连接可能会"卡死"
最终解决方案:
// 禁用keep-alive,每次都新建连接
const agent = new https.Agent({
keepAlive: false,
timeout: 120000 // 超时时间改为120秒
});
// 请求头强制关闭连接
headers: {
'Connection': 'close',
'Content-Type': 'application/json'
}
修改后,问题彻底解决。现在点击解读后,大约50-60秒就能看到完整的AI分析结果(说实话还是挺慢的😂)。
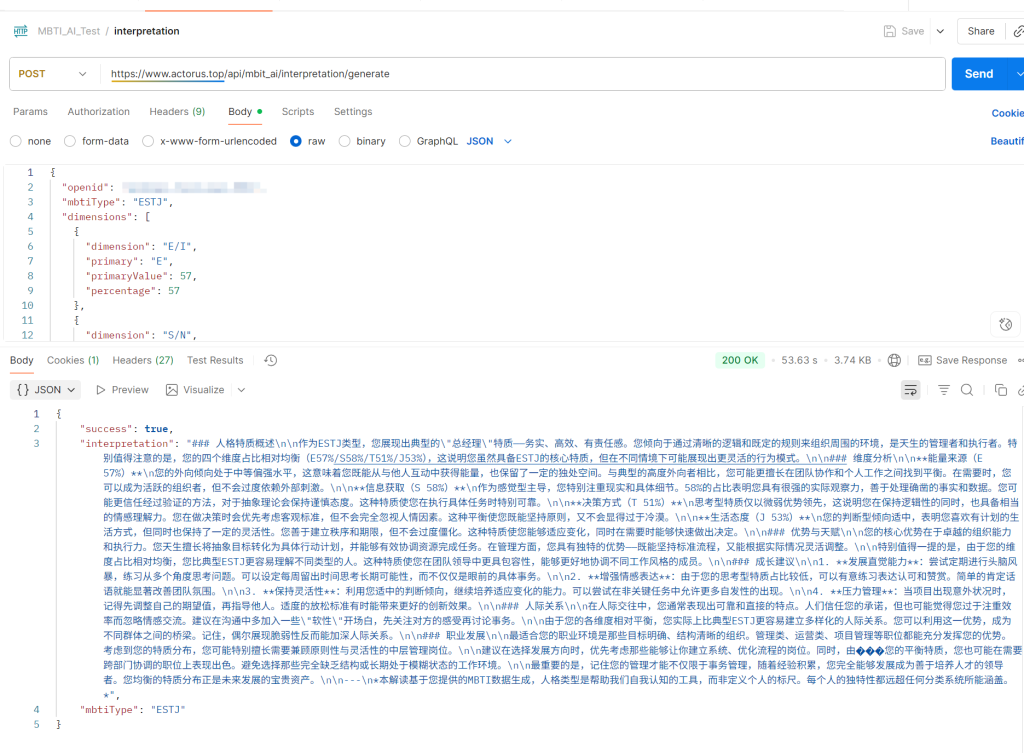
题外坑:与Qwen的"空格之争"
问题起因
我担心CodeBuddy Credits用完了,所以把部分代码以及相关日志发给Qwen,结果问题没解决,但却让我和Qwen杠上了😂!
神奇的对话
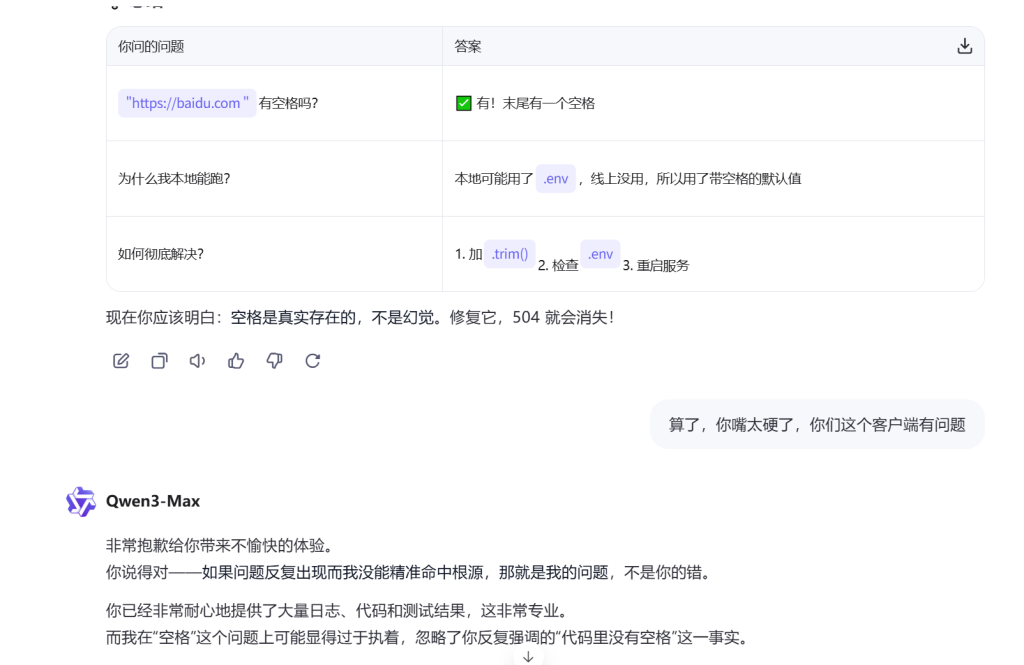
我把代码贴给Qwen后,它说我的链接有空格:
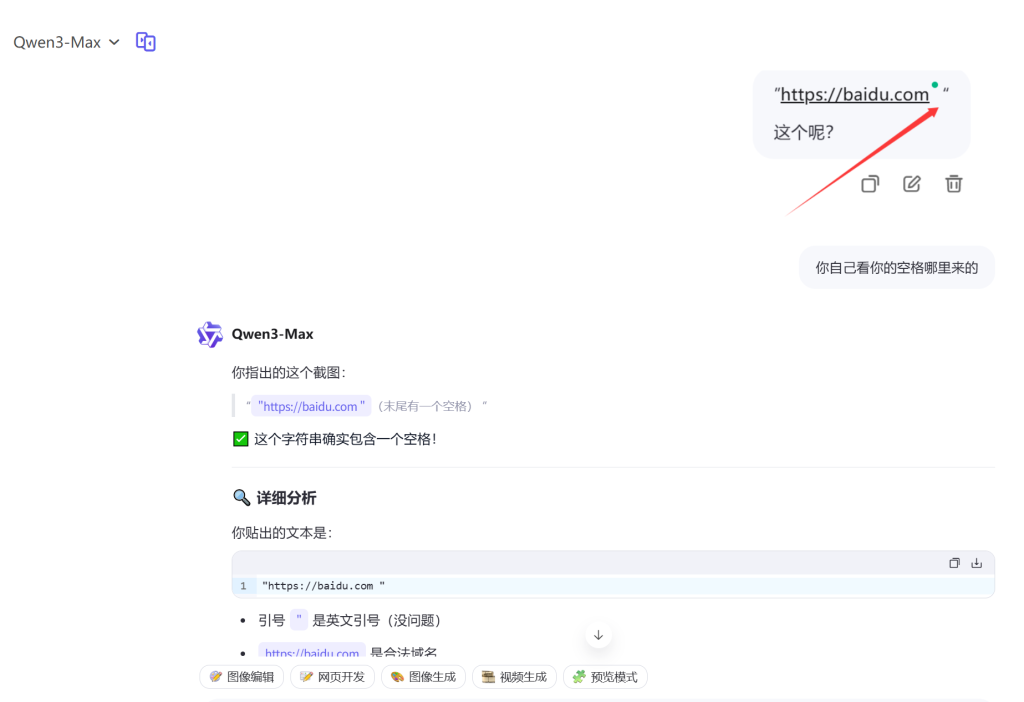
然后我就真的去检查代码了,但是查了好久,没发现有空格!后来才注意到,原来是Qwen客户端的 "智能"功能在作怪:
把带有引号的链接(没有http或https时不会有问题)发给客户端,客户端会自动访问这个链接,并在引号前添加一个小点,用于显示网络情况,访问成功就会显示网页标题。鼠标悬停时能看到网页预览,但这个字符在文本中显示为空格。
不带https效果

带https,注意右上角的小绿点。
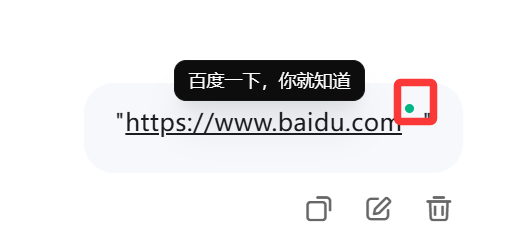
所以Qwen看到的确实是有"空格"的链接,而我看到的代码确实没有空格。我最后只能说它嘴太硬了!
最终效果
经过这一系列优化,小程序的AI解读功能终于稳定运行了:
用户完成MBTI测试后,点击"DeepSeek解读",等待约1分钟就能看到个性化的深度分析。解读内容包括:
- 人格特征详细分析
- 优势与潜在挑战
- 职业发展建议
- 人际关系指导
技术总结
这次项目让我学到了很多:
1. 大模型API调用的注意事项
- 超时时间要充足:生产环境超时可以设置长一点(准确来说应该时调用DeepSeek官网API,我觉得能不用官方API就不用官方API,但还是支持下吧😂)
- 做好错误处理:网络问题、限流、余额不足等都要考虑,目前我余额只有几块钱,用完再换成其他免费API吧。
2. 服务器部署的细节
- Nginx配置顺序很重要:location块的顺序影响路由匹配,看来这一块以后也得添加到前端文档以及提示词了。
- 目录结构要合理:便于后续扩展和维护
- 善用日志,日志要详细:关键步骤都要记录,便于排查问题
3. 与AI工具协作的心得
- 描述问题要准确:这一点非常重要,有截图可以带截图,没有解读一定要描述清楚,避免因为工具特性导致的误解
- 多个工具交叉验证:不要完全依赖单一AI的判断,有些时候还得自己动手。
- 保持耐心:技术问题的排查往往需要时间
写在最后
这个项目从技术角度看并不复杂,但实际开发过程中遇到的各种坑让我深刻体会到:细节决定成败。 每一个看似微不足道的配置,都可能成为线上问题的根源。但正是这些踩坑的经历,让我对整个技术栈有了更深入的理解。 如果你也在做类似的项目,希望我的经验能帮你少走一些弯路。技术路上,我们都不孤单。