微软开源文本转语音模型VibeVoice-1.5B:重塑TTS技术生态
文本转语音(TTS)技术作为人机交互的核心环节,正从“能发声”向“会说话”快速演进。近日,微软正式推出开源TTS模型VibeVoice-1.5B,不仅在Hugging Face平台开放模型权重与技术文档,更通过轻量化设计与高自然度表现,为开发者、企业及科研机构提供了全新的技术选择。本文将从模型特性、开源价值、应用场景及使用方式等维度,全面解析这一开源TTS领域的重要成果。
一、模型核心特性:平衡性能与实用性
VibeVoice-1.5B以“1.5B参数规模”为核心锚点,在音质自然度、多场景适配性与部署成本之间实现了精准平衡,其核心特性可概括为以下四点:
1. 参数规模与性能的最优解
相较于动辄10B以上参数的大型TTS模型,1.5B的参数规模显著降低了硬件部署门槛——开发者无需依赖高端GPU集群,仅通过普通服务器或甚至边缘设备(如高性能PC)即可完成模型加载与推理。同时,微软通过优化模型架构(如采用高效Transformer变体),确保语音生成质量不打折扣:生成语音的韵律、停顿与语调接近人类自然对话,避免了传统TTS常见的“机械感”。
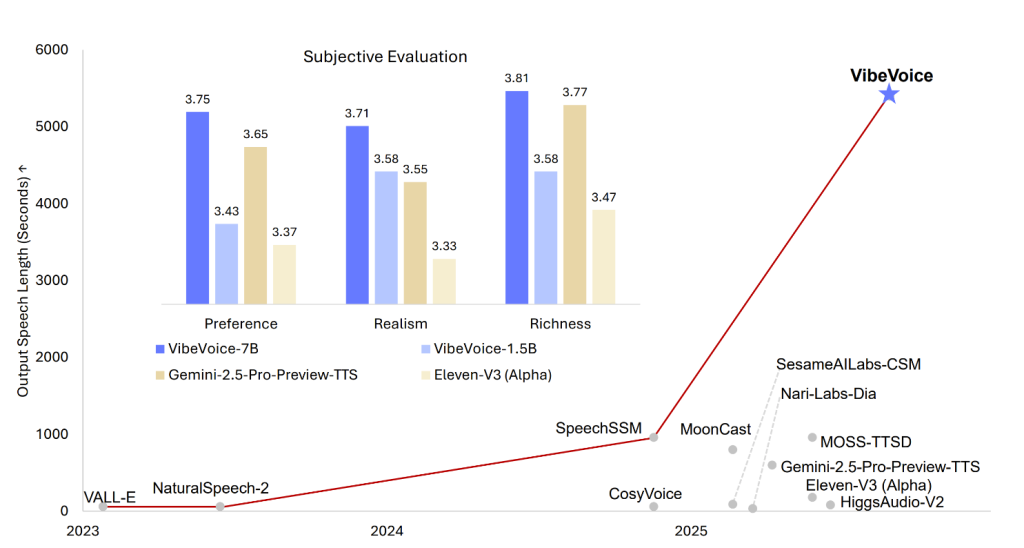
从Hugging Face平台公布的测试数据来看,VibeVoice-1.5B在“语音自然度评分(MOS)”中达到4.3/5.0,接近专业配音演员水平,可满足多数商业场景需求。
2. 多语言支持与全球化适配
针对跨地域应用需求,VibeVoice-1.5B原生支持中文(普通话)、英文、西班牙语、法语等10余种主流语言,并通过方言适配模块兼容中文粤语、四川话等变体。这一特性使其能直接服务于全球化产品,例如跨境电商的智能客服、多语言教育APP的语音播报等场景。
3. 情感与场景化语音生成
区别于单一语调的TTS模型,VibeVoice-1.5B具备“情感适配能力”:开发者可通过简单参数调节,让模型生成不同语气的语音,如新闻播报的“正式庄重”、智能助手的“亲切活泼”、儿童故事的“生动童趣”等。例如,在教育场景中,模型可模拟教师的温和语调;在企业通知场景中,又能切换为清晰严肃的播报语气。
4. 开源许可证保障商用自由
VibeVoice-1.5B采用Apache 2.0开源许可证,允许开发者免费用于个人项目、商业产品及二次开发,仅需保留原作者声明即可。这一许可证条款大幅降低了中小企业与个人开发者的使用成本,避免了“技术可用但商用受限”的尴尬。
二、开源价值:降低门槛,激活TTS生态创新
微软此次开源VibeVoice-1.5B,并非单纯发布一个模型,而是为TTS技术生态注入了“普惠化”动力,其核心价值体现在三方面:
1. 打破技术垄断,降低行业门槛
在此之前,高质量TTS技术多被少数科技巨头掌握,中小企业若想使用,需依赖API调用(如付费使用云厂商TTS服务)或投入数百万成本自研。VibeVoice-1.5B的开源,让开发者无需从零训练,即可直接获取工业级TTS能力,例如自媒体团队可免费搭建“文本转配音”工具,替代传统付费配音服务。
2. 推动社区协作与技术迭代
开源模型的生命力在于社区参与。开发者可基于VibeVoice-1.5B进行场景化微调——例如医疗领域可训练“专业术语语音库”,优化“CT”“核磁共振”等词汇的发音;方言保护项目可补充地方方言数据集,让模型支持更多小众语言。Hugging Face平台已开设模型讨论区,目前已有开发者分享“游戏角色语音微调方案”“有声书生成优化代码”等内容。
3. 提升技术透明度与安全性
闭源TTS模型常存在“黑箱问题”(如无法追溯语音生成逻辑),而VibeVoice-1.5B的开源代码与权重可被社区完全审查,能有效规避“恶意语音生成”“隐私泄露”等风险。例如,企业可通过审查模型代码,确保语音生成过程不采集用户文本数据,符合数据安全法规。
三、多元应用场景:从日常工具到产业升级
VibeVoice-1.5B的轻量化与高适配性,使其能覆盖个人、企业、公益等多类场景,以下为典型应用方向:
| 应用领域 | 具体场景案例 |
|---|---|
| 智能交互 | 智能家居语音助手(如“小爱同学”类产品,生成更自然的回复语音)、车载语音导航 |
| 内容创作 | 自媒体视频配音(如短视频旁白、课程录制)、有声书自动生成(将小说转为音频) |
| 无障碍服务 | 视障人群辅助工具(读取电子书、网页文本)、听障人群“语音转文字”反向适配 |
| 企业服务 | 智能客服语音回复(替代机械客服音,提升用户体验)、企业通知自动播报(如考勤提醒) |
| 教育领域 | 儿童早教APP(生成卡通语音讲解知识点)、语言学习工具(模拟母语者发音) |
四、快速上手:从Hugging Face获取与使用
VibeVoice-1.5B的部署与使用门槛较低,开发者可通过以下步骤快速体验:
1. 访问模型主页
打开Hugging Face模型页面:microsoft/VibeVoice-1.5B,页面提供模型权重、README文档、示例代码及语音生成demo。
2. 查看核心资源
- 模型权重:支持通过
transformers库直接加载,无需手动下载庞大文件; - 技术文档:详细说明模型输入输出格式、推理参数调节(如语速、语调、情感强度);
- demo演示:提供在线文本输入框,可实时生成语音并播放,直观测试模型效果。
3. 基础使用示例
通过Python代码即可快速调用模型(需提前安装transformers、torch等依赖):
from transformers import VibeVoiceProcessor, VibeVoiceForTextToSpeech
import torch
# 加载处理器与模型
processor = VibeVoiceProcessor.from_pretrained("microsoft/VibeVoice-1.5B")
model = VibeVoiceForTextToSpeech.from_pretrained("microsoft/VibeVoice-1.5B")
# 输入文本
text = "欢迎体验微软开源TTS模型VibeVoice-1.5B,让语音生成更简单。"
inputs = processor(text=text, return_tensors="pt")
# 生成语音(可调节语速:rate参数,范围0.8-1.2)
with torch.no_grad():
audio_output = model.generate(**inputs, rate=1.0)
# 保存语音为WAV文件
import soundfile as sf
sf.write("vibevoice_demo.wav", audio_output[0].numpy(), samplerate=24000)4. 部署建议
- 个人开发者:可在本地PC(需8GB以上显存)运行,用于生成个人配音;
- 企业用户:建议部署在云服务器(如AWS EC2、阿里云ECS),通过API封装供多终端调用;
- 边缘设备:可通过模型量化(如INT8量化)进一步降低显存占用,适配嵌入式设备。

五、总结:TTS技术进入“开源普惠”时代
微软VibeVoice-1.5B的开源,不仅是一次技术发布,更标志着TTS领域从“封闭商用”向“开源协作”的重要转折。对于开发者而言,它提供了零成本获取高质量TTS能力的途径;对于行业而言,它将加速TTS技术在教育、医疗、企业服务等领域的落地;对于用户而言,未来将迎来更自然、更多元的语音交互体验。
随着社区对模型的持续优化与微调,VibeVoice-1.5B有望在不久后覆盖更多语言、更多场景,成为TTS生态的“基础构建块”。若你是开发者、创业者或技术爱好者,不妨访问Hugging Face页面,亲自体验这一开源模型的魅力。
参考资料: