文本转语音巅峰大模型——一键整合包
最近白嫖的语音克隆额度都用完了,没办法又得用,刚开始把前面语音克隆工具拿出来用了,但发现文本一长吞字太严重,折腾了一下午都没能解决!上了gayhub,想在issue里面看能不能解决这个问题,发现都在反馈这个问题,还有人居然研究了两天都没搞定这个问题。故弃用之!之前分享的夸克网盘链接也取消了。前几天看到Fish Audio 发布了OpenAudio-S1,并开源了其0.5B版本OpenAudio-S1-mini,所以想着能不能用这个替换目前的语音克隆。所以就有了这篇文章。
OpenAudio?Fish Speech?
大概说下这个关系,Fish Speech改名为OpenAudio,OpenAudio模型基于Fish Speech模型,Fish Audio最新模型名称为OpenAduio-S1。但gayhub上的仓库还是叫Fish Speech,所以最后我们的一键整合包也叫fish_speech。
项目亮点
1. 顶级的合成质量
Fish Speech最新的OpenAudio S1模型在TTS-Arena2上拿到了第一名!这可不是吹的,人家是有真实数据支撑的:
- 英语文本的词错误率(WER)只有0.008
- 字符错误率(CER)只有0.004
这个数据意味着什么?就是合成出来的语音几乎和真人说话一样准确!
2. 丰富的情感控制
这个功能真的让我眼前一亮。你可以在文本中加入各种情感标记,比如:
- 基础情感:
(angry)(sad)(excited)(surprised)等 - 高级情感:
(disdainful)(anxious)(sarcastic)等 - 语调控制:
(whispering)(shouting)(soft tone)等 - 特殊音效:
(laughing)(crying loudly)(sighing)等
想象一下,你可以让AI用讽刺的语调说话,或者加上笑声,这种可控性真的太棒了(说话实说我不会用,留给大家尝试吧,关键平时也用不到)!
3. 零样本语音克隆
只需要提供一段参考音频,就能克隆出对应的声音。一键包带了40多个内置音色,包括各种风格的中文声音,以及英文音色,应有尽有。
4.跨语种克隆
原样本为中文,想让他说英文,或者其他语言?
这是太乙真人原声
让太乙真人说段英文?
Your joke wasn't funny at all — I was laughing because I choked on chicken feathers!(in a laughing tone)
使用体验分享
部署过程
说实话,非常顺利!
- 环境要求我用的是3060显卡+64G内存,完全够用,1060也可以跑起来,但慢一些。
- 模型下载https://wxa.wxs.qq.com/tmpl/mr/base_tmpl.htmlopenaudio-s1-mini模型大小适中,下载不算太痛苦。
界面使用
项目提供了两种使用方式:
WebUI界面:功能完整,适合在浏览器中使用,界面简洁明了,我一键整合包也保留了这种启动方式。
Qt GUI界面:这个项目本身不提供QtGUI界面的,但有单独的界面,我嫌麻烦,就直接用了之前CosyVoice自己写的那个界面:
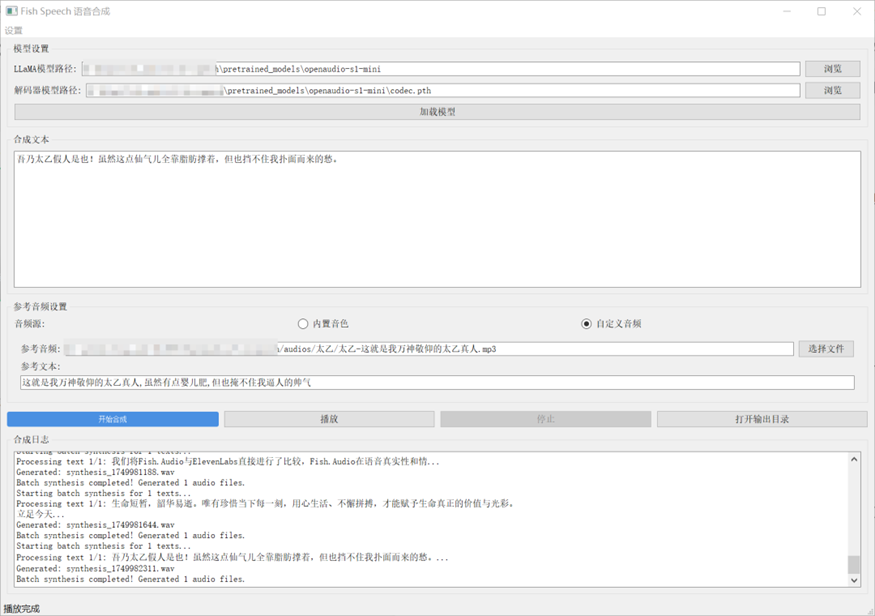
相比webui,多了个内置音色(从之前腾讯云语音合成那里d的)。使用时可以直接从下拉菜单中选择各种预设音色,不用自己去找参考音频文件。
解压后是这样的,双击run_gui.bat或run_webui.bat都可以:
实际合成效果
这是太乙假人
吾乃太乙假人是也!虽然这点仙气儿全靠脂肪撑着,但也挡不住我扑面而来的愁。你讲的这个笑话,一点儿都不好笑,我笑是因为我喉咙卡鸡毛了。哪吒原声
我乃哪吒三太子,放纵不羁爱作诗,双手插兜大步走,曲道也能踩成直
哪吒克隆
突然,病毒细菌军团来袭,它们张着血盆大嘴,发出渗人的怪笑,直奔孩子们!孩子们的命运会如何?是遭受病毒细菌的无情侵袭,还是继续快乐地歌唱?
OpenAudio官网播音主播
璀璨的星河在广袤的天际延伸,五千年文明的灿烂华章在这片热土上绽放。看,这是一个充满希望的时代,我们共同见证着中华民族伟大复兴的光辉历程。让我们携手同行,创造更加辉煌的明天。
克隆版本
生命短暂,韶华易逝。唯有珍惜当下每一刻,用心生活、不懈拼搏,生命真正的价值与光彩。立足今天,无悔耕耘,方能更好地迎接明天。时光的真相在于:“流光容易把人抛,红了樱桃,绿了芭蕉”。若待他日回首,唯一能免于悔恨的,便是把握住当初的分分秒秒——视每一天为上天的特别恩赐,全力活出精彩。生命的真谛,不在于长度,而在于深度:在于是否奋力拼搏过,是否付出奉献过。正如箴言所启:“把有限的生命,投入到无限的为人民服务中去。”生命的意义在于奋斗与积累,保持平静心态,戒除贪求。“无可奈何花落去,似曾相识燕归来”,当惜取此刻,莫负时光恩惠。
与CosyVoice的对比
既然提到了CosyVoice,就大概对比一下:
| 特性 | Fish Speech | CosyVoice |
|---|---|---|
| 合成速度 | 慢 | 快 |
| 吞字问题 | 几乎没有 | 严重 |
| 音质效果 | 优秀 | 良好 |
总结:如果你追求速度,可以试试CosyVoice(如果不在意吞字的话);但如果你要质量和稳定性,Fish Speech绝对是更好的选择。特别是对于需要处理长文本或者对准确性要求高的场景,Fish Speech的优势非常明显。https://wxa.wxs.qq.com/tmpl/mr/base_tmpl.html
一些小建议
- 硬件要求建议至少8G显存,我的3060勉强够用,但如果要处理更长的文本,显存可能会紧张;
- 文本处理长文本还是建议分段处理,虽然不会吞字,但分段后效果会更好;
- 音色选择多试试不同的内置音色,每个都有自己的特色;
- 情感标记说实话,我没试出来,可能是我不会用?
写在最后
以下是各种地址,大家最喜欢的环节!
项目地址:https://github.com/fishaudio/fish-speech
在线体验:https://fish.audio