阿里万亿参数大模型 Qwen3-Max-Preview:不止编程反超,多语言与商业化布局同步破局
前一天 Anthropic 刚有新动作,阿里就紧接着在深夜放出了重磅消息 —— 推出旗下史上参数规模最大的模型 Qwen3-Max-Preview,参数量直接突破万亿。这个数字一出来,不少关注 AI 的人都眼前一亮,要知道,从之前的千亿参数跃升到万亿,可不是简单的数量叠加,背后藏着的技术突破和性能提升才是关键。
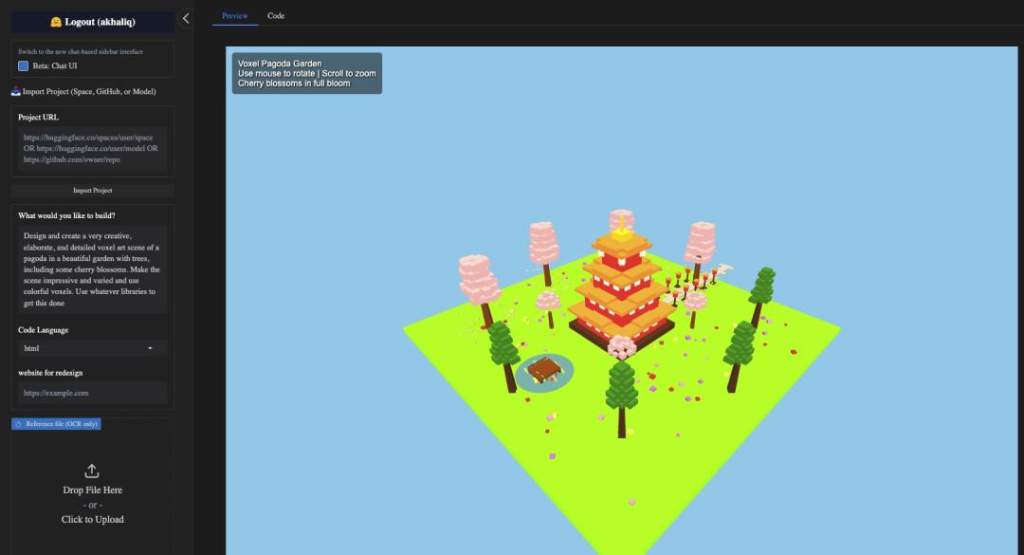
先说说大家最关心的实测体验吧。现在想试试这个模型很方便,只要在 Qwen Chat 的模型下拉菜单里选中 Qwen3-Max-Preview 就能直接用,官网还开放了 API 接口,开发者也能通过阿里云平台调用。之前有国外的博主在 HuggingFace 的 AnyCoder 项目里做了个测试,让模型设计一个带樱花树的花园佛塔像素艺术场景,要求既创意又详细,还得用彩色像素呈现。没想到 Qwen3-Max-Preview 一次性就给出了能直接运行的代码,生成的场景不仅细节丰富,色彩搭配也很协调,用鼠标还能旋转、缩放查看,互动感拉满。
我自己也在官网试了试,让它生成一个庆祝 Qwen3-Max 发布的落地页。本来以为要等一会儿,结果几秒钟就出了完整的 React 代码,不仅有页面结构,还加了彩色纸屑的动画效果,文字部分也写得很到位,比如 “新一代 AI 智能已到来,体验前所未有的算力、创造力与能力”,连页面的响应式设计都考虑到了,打开预览就能看到完整的效果,响应速度确实让人惊喜。
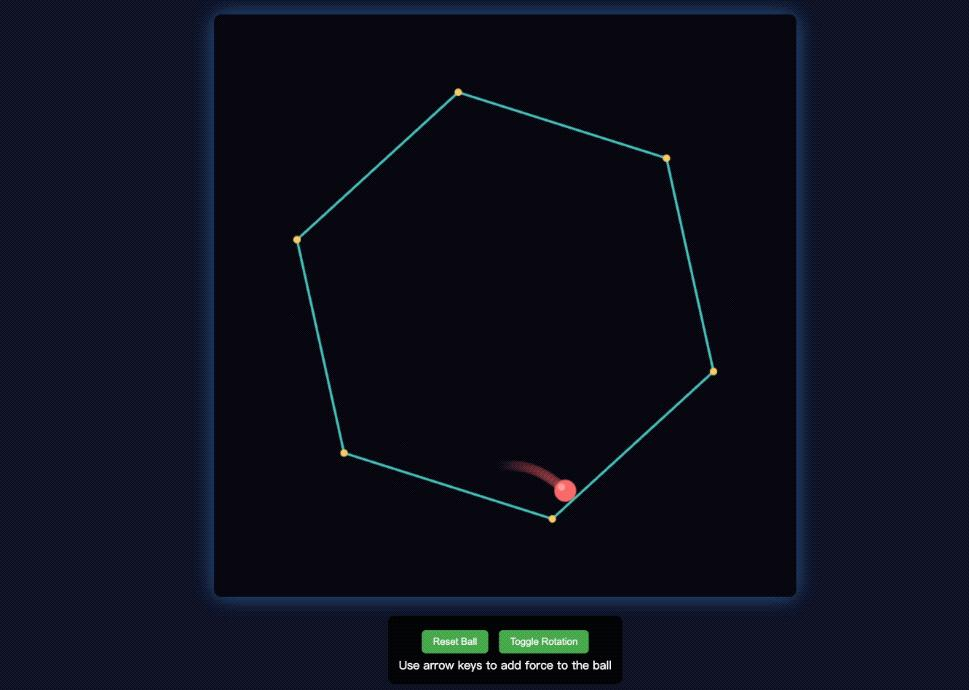
后面又加大了难度,选了经典的编程问题 —— 弹跳球模拟碰撞。我让模型写一段 JavaScript 代码,实现小球在旋转的六边形里弹跳,还要考虑重力和摩擦力,碰撞墙壁时得符合物理规律。生成的代码运行后,小球真的能沿着六边形内壁弹跳,用向上键给小球加力时,它会立刻加速,下落时也能明显看到重力的作用。后来我把小球数量调到 10 个,运行起来依然很流畅,屏幕上显示的碰撞次数很快就超过了 3 万次,每个小球的运动轨迹都很自然,没有出现卡顿或错位的情况。
还有人尝试让它生成《愤怒的小鸟》小游戏,模型也顺利给出了 HTML 和 CSS 代码,游戏里能显示关卡、分数和剩余小鸟数量,还能重置关卡、进入下一关。不过因为初始提示词比较简单,游戏里怪物的位置有点偏差,要是再把需求写得详细点,效果应该会更好。
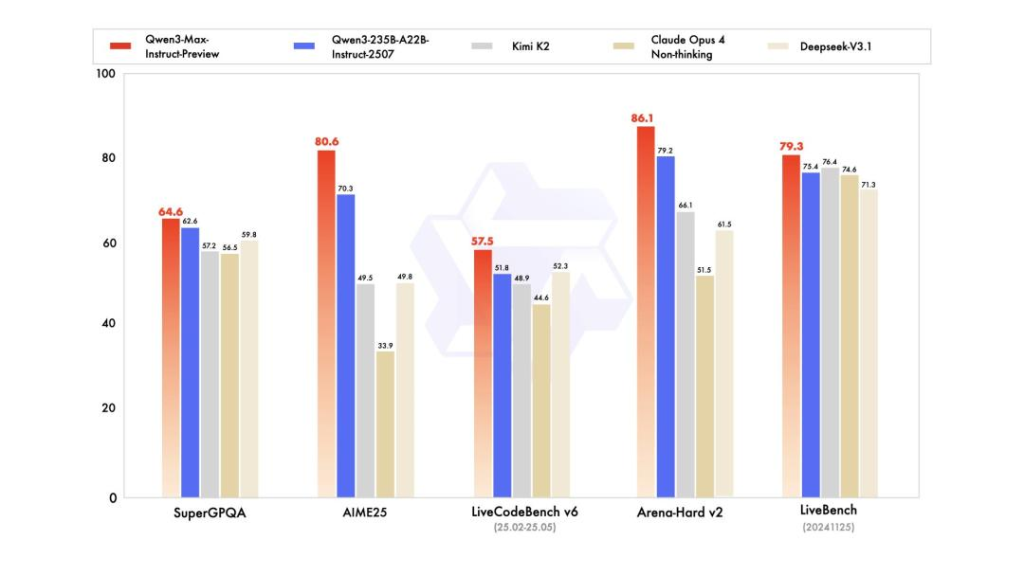
除了实测表现,Qwen3-Max-Preview 在基准测试里的成绩也很亮眼。从官方公布的数据来看,它在 SuperGPQA、AIME2025、LiveCodeBench V6 等多个权威测试中,都超过了 Kimi K2、Claude Opus 4(Non-thinking)和 DeepSeek-V3.1 这些热门模型。尤其是编程能力,之前 Claude Opus 4 在业内几乎是编程领域的标杆,这次 Qwen3-Max-Preview 直接实现了反超,不少网友在社交平台上留言 “居然击败了 Opus?”,满是惊讶。阿里在推文中提到的 “Scaling works(规模化扩展是有效的)”,或许正是这次突破的关键 —— 随着模型参数、数据量和计算量的指数级增长,模型能力确实实现了质的飞跃。
这次升级还有一个大亮点,就是多语言支持。以前不少国产大模型在小语种处理上总有短板,而 Qwen3-Max-Preview 一下子兼容了 100 多种语言,不管是跨语言翻译,还是用小语种进行常识推理,表现都达到了行业领先水平。比如用冷门的小语种提问 “如何用传统方法制作当地特色美食”,模型不仅能准确理解问题,还能详细列出步骤,甚至补充食材的替代方案。另外,研发团队还针对检索增强生成(RAG)和工具调用做了专项优化,现在模型调用外部知识库或第三方工具时,适配性更强了,比如在科研场景中,它能快速检索学术文献,还能调用数据分析工具生成图表,大大减少了人工操作的步骤。不过目前这个版本还没有集成深度思考功能,官方说后续会逐步完善。
在性能细节上,Qwen3-Max-Preview 也有不少进步。对比 2025 年 1 月的版本,它在数学计算、逻辑推理和科学问题解决上的准确率提高了不少,处理中英文混合指令时,响应的可靠性提升了超过 40%。比如让它解决一道复杂的物理力学题,不仅能给出正确答案,还能分步骤解释原理,公式推导也很清晰;用中英文混合提问 “如何用 Python 实现机器学习模型的特征工程,需要包含缺失值处理和特征标准化”,模型给出的代码和说明既准确又易懂,没有出现之前偶尔会有的 “幻觉内容”。研发团队说,这主要得益于注意力机制的优化和知识蒸馏技术的改进,让模型在处理长文本和专业知识时更高效、更精准。
商业化方面,Qwen3-Max-Preview 也给出了明确的定价方案。根据 OpenRouter 平台的信息,模型的输入服务收费是每百万 tokens 1.20 美元,大概折合人民币 8.6 元,输出服务是每百万 tokens 6 美元,约 42.8 元人民币。这个价格在当前的大模型市场里算比较有竞争力的,尤其是对中小开发者和初创企业来说,降低了尝试高端模型的门槛。行业分析师认为,这样的定价策略能让模型更快落地到更多场景中,比如中小企业的智能客服、在线教育平台的辅导工具,还有科研机构的数据分析项目,都能以较低成本用上高性能模型。
其实阿里能在大模型领域实现 “后来者居上”,背后的策略很清晰。一方面是靠开源拉近距离,从 2023 年开始,阿里就陆续开源了 Qwen 系列的多个版本,从 70 亿参数的 Qwen-7B,到 140 亿、720 亿参数的模型,再到视觉、音频等多模态版本,几乎覆盖了所有主流尺寸和应用场景。而且不只是开放模型权重,还提供商业化授权,这让很多中小企业和个人开发者愿意围绕 Qwen 生态做创新,很快就在 Hugging Face 等全球顶级开源社区积累了大量用户,也收集到了很多真实的应用数据,这些数据反过来又能帮助模型优化。
另一方面,阿里云的支撑也很关键。大模型训练和推理是出了名的 “算力吞金兽”,阿里云不仅为 Qwen 团队提供了稳定高效的超大规模计算集群,还整合了从数据标注、模型开发,到分布式训练、部署推理的全链路工具。研发团队不用在工程细节上花费太多精力,能专心攻克算法和模型创新的难题。而且借助阿里云的 MaaS(模型即服务)战略,企业客户不用从零开始训练模型,直接调用 Qwen 的 API,或者用平台工具对开源模型做微调,就能快速搭建自己的 AI 应用。这种 “模型 + 云” 的组合,让技术从研发到落地的路径变得特别短。
不过,Qwen3-Max-Preview 的发展之路也不是没有挑战。最核心的问题就是开源和收益的平衡。现在大家能免费获取性能不错的开源模型,甚至可以私有化部署,那愿意花钱用阿里云付费服务的企业会有多少呢?这就要求阿里云不能只做简单的模型托管,必须拿出更有吸引力的东西 —— 比如比开源版本更好的性能优化,能应对高并发场景;更全面的安全保障,满足企业的数据隐私需求;还有专门的企业级工具链,帮客户解决定制化问题。只有这样,才能把庞大的开源用户群体转化成高价值的付费客户,这也是阿里接下来要跨过的一道坎。
另外,AI 行业的人才竞争越来越激烈,核心人才的流失也是一个隐患。之前包括贾扬清在内的一些 AI 框架和基础设施领域的关键人物离开阿里,虽然对阿里这样的大公司来说,不至于动摇根基,但多少会影响团队士气,也可能给项目的长期战略延续性带来不确定性。而且这些离开的人才,很多会投身创业,或者加入其他巨头企业,他们对阿里的技术体系和优劣势很了解,未来可能会在细分领域形成竞争压力。所以,怎么在激烈的竞争中留住核心人才,同时吸引更多顶尖人才加入,建立稳定的人才梯队,也是阿里需要长期面对的问题。
总的来说,Qwen3-Max-Preview 的发布,确实让国产大模型在全球第一梯队里占据了更重要的位置。万亿参数的突破、编程能力的反超、多语言支持的完善,还有 “开源 + 云” 的落地路径,都展现出阿里在 AI 领域的实力和野心。但接下来的路更关键 —— 开源模式能不能持续盈利,能不能在技术上一直跟上甚至超越闭源巨头,能不能解决人才留存的问题,这些都会决定 Qwen 未来能走多远。毕竟现在 AI 行业的竞争还在白热化阶段,只有把这些问题都解决好,阿里才能真正从 “后来者” 变成持续的 “领跑者”,而这不仅关系到阿里自身的发展,也会影响整个国产大模型行业的走向。